Engineering Consumption Analytics for Apple Podcasts: figuring out how people listen inside a Faraday cage

One of the most common requests we get from podcast content producers is more analytics. Understanding how, where, and what people listen to is a critical part of the feedback loop to grow their audience.
Like many in the industry we’re looking forward to Apple releasing the much anticipated Podcast Analytics on Podcasts Connect. We believe this new data into how Apple Podcasts listeners consume content will help podcasters refine and improve their content and further improve transparency for podcast advertisers.
After the general availability of Podcast Analytics we will be sunsetting our Consumption Analytics for Apple Podcasts feature which we’ve had the opportunity to showcase to select customers, a number of partners and Apple themselves since 2016. We will also be exploring ways to integrate the new data into our platform once available to us from Apple to enrich the analytics data our customers already have to build a comprehensive report of listening habits across web and mobile.
We would like to take this opportunity to share the methodology we developed that made it possible to sample listening behaviour in Apple Podcasts — a media player without third-party reporting capabilities — to hopefully help inspire the podcast community to keep innovating on better analytics methodologies.
The challenge: Apple Podcasts (the Faraday cage)
For many podcasters, Apple Podcasts listeners are their biggest audience by downloads. The app’s de-facto status in iOS has helped surface podcasts into the hands of millions of iPhone and iPad users around the world. At Omny Studio we’re seeing on average over 60% of all podcasts downloaded with Apple Podcasts.

For the most part podcast apps — like Apple Podcasts — are usually “dumb clients”. That is they simply download RSS and MP3/AAC files from a web server. It’s simple and you could argue its pros and cons but the fact is there’s no functionality in the “podcast specification” to allow for playback analytics pings or callback (among many other things).
Thankfully most — if not all — podcast hosting providers (including Omny Studio) provide a range of download analytics data generated by the download requests for the media file. By parsing and processing IP address and user-agents we can anonymously geo-locate listeners and identify which app, device, and platform they’re using (whilst filtering superfluous downloads from bots/crawlers and duplicate downloads).
The tricky part of podcast download analytics is that there is no direct correlation between downloads and listening. Sometimes episodes get played after they’re downloaded, sometimes they get played while they’re downloading, and other times they don’t even get played at all after download.
By analyzing different combinations of HTTP request headers and sequences (both the RSS feed and the episode file) we are able to isolate some Apple Podcasts downloads on our platform as playing progressive downloads or “streamed plays” (being played at the same time it is downloaded as opposed to a non-playing background download).
But it’s important to remember that the Apple Podcasts app will continue to download and buffer the entire file as it is playing. On a fast WiFi or 4G internet connection downloading from a content delivery network a significant chunk of the episode (or even the entire episode) can be downloaded in a matter of seconds.
As such, the current industry practice of analyzing partial progressive downloads (bytes served from the server to the app) is not able to accurately differentiate active listening or how much of the content is listened to.
We wondered if we could turn this problem upside down 🤔.
The solution: “Streaming” in real-time
In an age where there’s an ever-increasing thirst for more data and faster data speeds, sometimes the answer is to actually slow down a bit.
The consumption analytics system for Apple Podcasts we developed employed a rate-limited progressive download in “real-time” to progressively downloaded or “streamed plays” which allowed us to essentially “follow” the listener and identify when users play, pause, and skip throughout the audio file.
We achieved a “real-time” stream by artificially restricting the transmission rate between the server and the client to the same bitrate as the audio file (e.g. 128Kbit/s for a MP3 file encoded at 128Kbit/s). This is possible because we encode the audio files we publish using a constant bitrate which ensures that every second is equal in data length.
Even at the high end of the bitrate for podcasts, it is still a fairly low bandwidth stream which means it is practical for both listeners on fast WiFi/4G connections as well as slower 3G connections.
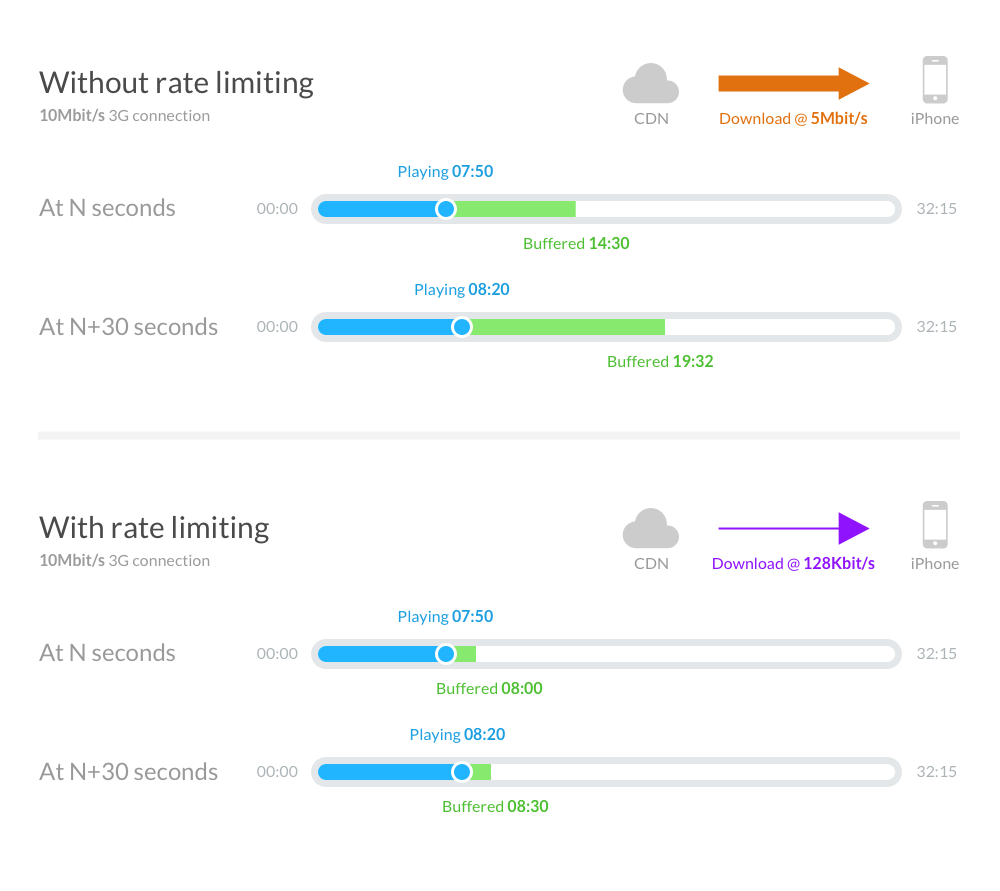
We observed the Apple Podcasts app would behave predictably when manipulating playback — so when a user stops the audio the app would stop requests, or when a user seeks, the app would start a new range request. This meant that we could confidently analyze the bytes served and calculate the corresponding play time of the audio to build a consumption model of the listening session.
A listening session was able to be uniquely isolated by a combination of various identifiers including but not limited to the HTTP header “X-Playback-Session-ID” which is a random GUID that Apple Podcasts sent for a “session”. This made it possible to infer the same listener was listening even if their connection changed from one network to another (WiFi to mobile) or is from a shared network with other Apple Podcasts users (e.g. a workplace sharing one public IP).
We ran this system in production with a set of proxy servers running nginx (configured with the rate_limit flag on the ngx_http_core_module) that proxied our download servers and served MP3 only to Apple Podcasts users (by user-agent).
We periodically parsed the nginx server logs to reconstruct listen events from byte-ranges and sent “play & pause” consumption events to our primary analytics servers to build the beautiful graphs and stats our customers can access.
In our internal tests with the iOS 10 version of Apple Podcasts (in 2016) and our production servers over WiFi and 3G connections, we were able to achieve consumption reporting accuracy to within 10 seconds of actual play, pause and skip events.
Of course this system wasn’t perfect and there were a number of limitations, some of which we could workaround and others we could not.
Workarounds and shortcomings
By rate-limiting the download, there was a slight impact on the listener experience. We tried to balance and minimize this impact where possible while still maintaining the integrity of the analytics data.
The first impact was on the initial load. Even on a fast content delivery network, tapping start on a MP3 file can take a couple seconds to play. Besides the network-level HTTP connection and SSL negotiations, part of the delay comes from the fact that MP3 files have ID3 and XING/INFO metadata at the “start” of the file. While this metadata isn’t significantly large, it would still take many seconds to download on a throttled connection.
We addressed the initial load impact by allowing the connection to initially “burst” (download as fast as possible) the download for 5 seconds. This allowed the app to download the metadata as well as the initial few seconds of audio as quickly as it could so there was no impact to the user compared to a traditional download.
When processing the partial download logs, our algorithms took into account that initial requests had a burst of audio data delivered and waited for further correlating requests before assuming the initial burst of audio was heard.
The second impact was during playback. Sometimes, more often on mobile connections, downloads can be interrupted by connection issues (such as moving in and out of reception). Media applications utilize a buffer to allow for the download to continue at a different speed than playback to mitigate this. But because we’re rate-limiting the download, the app does not have the opportunity to download a long buffer.
We addressed this by ensuring the app had roughly a 10 second buffer, so short momentary connection issues could still be buffered. We balanced this buffer to be long enough so short interruptions could be mitigated, while short enough so the accuracy of our consumption events could still be guaranteed.
We acknowledged that even with both workarounds, the playback experience was not perfect and could have an impact on listener experience. We worked closely with various customers to ensure they were aware of the limitations before opting-in to the system which randomly sampled only a fraction of their Apple Podcasts streamed plays.
Of course, the biggest shortcoming of all is that downloaded plays (either manually downloaded by the user or automatically downloaded in the background by Apple Podcasts) could still not be tracked since it makes no subsequent download request to the server.
Where to from here?
From the moment we announced the functionality we had a pretty steady stream of enquiries. These ranged from asking from how it worked, to how soon customers can have it enabled, to questioning how it was even possible.
We’ve always wanted to answer the questions we couldn’t — divulging the ingredients of a secret sauce is not always a good idea. However with Apple about to provide the consumption data first-hand and given we will be sunsetting this feature, we believe there is value in sharing our methodology with the industry.
We acknowledge the system we developed is not perfect nor comprehensive enough to replace other methodologies but the ability to peek into the Faraday cage — if only a little bit — was worth the hassle.
We look forward to the insight that Apple will be providing to the industry which we hope to integrate so that we can help paint the fullest picture of podcast listening possible for all of our customers.
While Apple’s cage may the biggest it isn’t the only one. The landscape is saturated with different apps, devices, and platforms. We’ll need many more brushes to complete the picture so we will continue to develop new methodologies and systems to add color to the conversation.
So here’s to all the creators, advertisers, platforms, and everyone else in the podcast industry helping to grow and mature the ecosystem. 2018 should be quite a year for all of us and we can’t wait.