Analyser la consommation de podcasts pour Apple Podcasts : comprendre comment les gens écoutent dans une cage de Faraday

Une des demandes les plus courantes que nous recevons de la part des producteurs de contenu podcast est davantage d'analyses. Comprendre comment, où et ce que les gens écoutent est une partie essentielle de la boucle de rétroaction pour développer leur audience.
Comme beaucoup dans l'industrie, nous attendons avec impatience la sortie très attendue de Podcast Analytics sur Podcasts Connect par Apple. Nous croyons que ces nouvelles données sur la manière dont les auditeurs d'Apple Podcasts consomment du contenu aideront les podcasteurs à affiner et à améliorer leur contenu et à accroître la transparence pour les annonceurs de podcasts.
Après la disponibilité générale de Podcast Analytics, nous retirerons notre fonctionnalité de Consommation Analytics pour Apple Podcasts, que nous avons eu l'occasion de présenter à des clients sélectionnés, à plusieurs partenaires et même à Apple eux-même depuis 2016. Nous explorerons également des moyens d'intégrer les nouvelles données dans notre plateforme une fois qu'elles seront disponibles pour nous auprès d'Apple afin d'enrichir les données analytiques que nos clients possèdent déjà pour construire un rapport complet sur les habitudes d'écoute sur le web et sur mobile.
Nous aimerions profiter de cette occasion pour partager la méthodologie que nous avons développée qui a rendu possible l'échantillonnage du comportement d'écoute sur Apple Podcasts — un lecteur multimédia sans capacités de reporting tiers — dans l'espoir d'inspirer la communauté podcast à continuer d'innover sur de meilleures méthodologies d'analyse.
Le défi : Apple Podcasts (la cage de Faraday)
Pour de nombreux podcasteurs, les auditeurs d'Apple Podcasts constituent leur plus grande audience par téléchargements. La position de facto de l'application sur iOS a permis de rendre les podcasts accessibles à des millions d'utilisateurs d'iPhone et d'iPad dans le monde. Chez Omny Studio, nous observons en moyenne plus de 60% de tous les podcasts téléchargés avec Apple Podcasts.

Pour la plupart, les applications de podcast — comme Apple Podcasts — sont généralement des "clients stupides". C'est-à-dire qu'ils téléchargent simplement des fichiers RSS et MP3/AAC depuis un serveur web. C'est simple et on peut argumenter sur ses avantages et ses inconvénients, mais le fait est qu'il n'y a pas de fonctionnalité dans la "spécification de podcast" permettant de réaliser des pings d'analyses de lecture ou des rappels (entre autres).
Heureusement, la plupart — sinon tous — les fournisseurs d'hébergement de podcasts (y compris Omny Studio) fournissent une gamme de données d'analyses de téléchargement générées par les demandes de téléchargement du fichier multimédia. En analysant et en traitant les adresses IP et les agents utilisateur, nous pouvons localiser de manière anonyme les auditeurs et identifier quelle application, quel appareil et quelle plateforme ils utilisent (tout en filtrant les téléchargements superflus des bots/crawlers et les téléchargements dupliqués).
La partie délicate de l'analyse des téléchargements de podcasts est qu'il n'y a pas de corrélation directe entre les téléchargements et l'écoute. Parfois, les épisodes sont lus après leur téléchargement, parfois ils sont lus pendant leur téléchargement, et d'autres fois ils ne sont même pas lus du tout après le téléchargement.
En analysant différentes combinaisons d'en-têtes de requête HTTP et de séquences (à la fois le flux RSS et le fichier d'épisode), nous sommes en mesure d'isoler certains téléchargements Apple Podcasts sur notre plateforme comme étant des téléchargements progressifs ou des "lectures en continu" (en cours de lecture en même temps qu'ils sont téléchargés par opposition à un téléchargement en arrière-plan sans lecture).
Mais il est important de se rappeler que l'application Apple Podcasts continuera de télécharger et de mettre en mémoire tampon l'intégralité du fichier pendant la lecture. Sur une connexion Internet WiFi ou 4G rapide, télécharger depuis un réseau de diffusion de contenu une partie importante de l'épisode (voire l'intégralité de l'épisode) peut être téléchargé en quelques secondes.
En tant que tel, la pratique industrielle actuelle d'analyse des téléchargements progressifs partiels (octets servis du serveur à l'application) n'est pas en mesure de différencier avec précision l'écoute active ou la quantité de contenu écoutée.
Nous nous sommes demandé si nous pouvions inverser ce problème 🤔.
La solution : "Streaming" en temps réel
À une époque où il y a une soif croissante de données et des vitesses de données plus rapides, parfois la réponse est en fait de ralentir un peu.
Le système d'analyse de consommation pour Apple Podcasts que nous avons développé utilisait un téléchargement progressif limité en "temps réel" pour les lectures téléchargées progressivement ou les "lectures en continu", ce qui nous permettait essentiellement de "suivre" l'auditeur et d'identifier quand les utilisateurs jouent, mettent en pause et sautent tout au long du fichier audio.
Nous avons atteint un flux "en temps réel" en limitant artificiellement le débit de transmission entre le serveur et le client au même débit que le fichier audio (par exemple, 128 Kbit/s pour un fichier MP3 encodé à 128 Kbit/s). C'est possible parce que nous encodons les fichiers audio que nous publions en utilisant un débit binaire constant qui garantit que chaque seconde est égale en longueur de données.
Même au niveau élevé du débit binaire pour les podcasts, il s'agit toujours d'un flux à bande passante assez faible, ce qui signifie qu'il est pratique à la fois pour les auditeurs sur des connexions WiFi/4G rapides et pour des connexions 3G plus lentes.
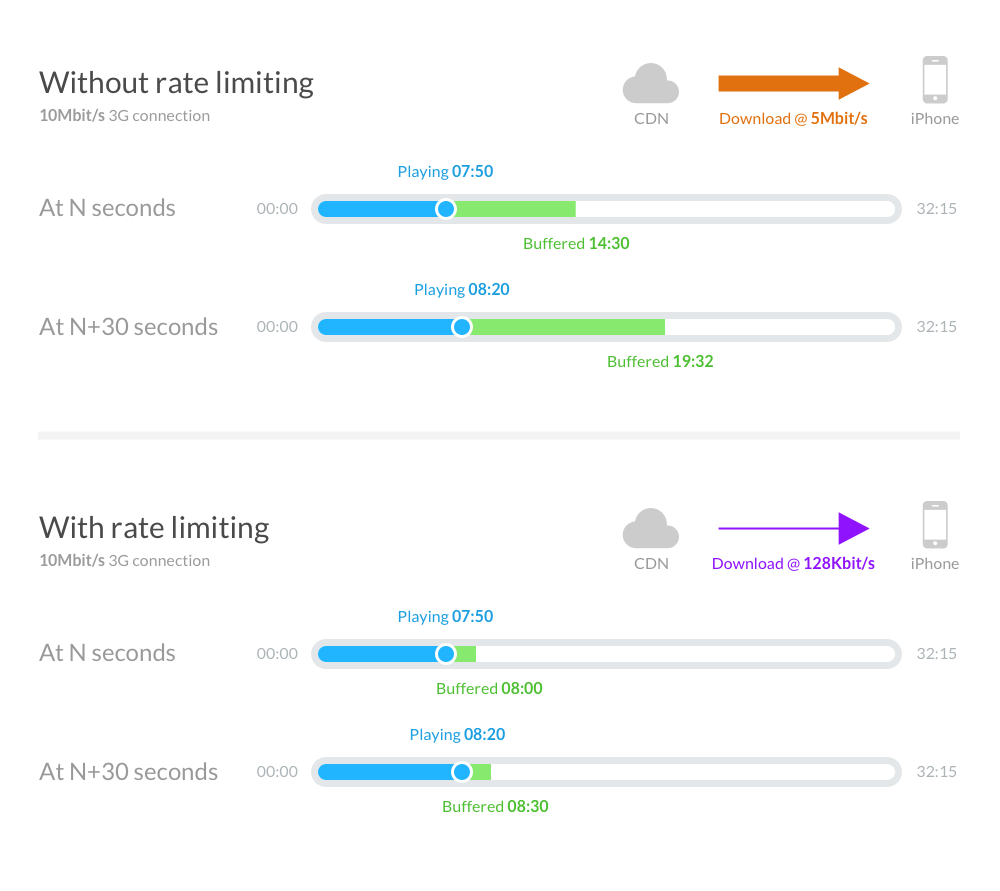
Nous avons observé que l'application Apple Podcasts se comportait de manière prévisible lors de la manipulation de la lecture — ainsi, lorsque l'utilisateur arrêtait l'audio, l'application arrêtait les requêtes, ou lorsque l'utilisateur effectuait une recherche, l'application commençait une nouvelle requête de plage. Cela signifiait que nous pouvions analyser avec confiance les octets servis et calculer le temps de lecture correspondant de l'audio pour construire un modèle de consommation de la session d'écoute.
Une session d'écoute pouvait être isolée de manière unique par une combinaison de divers identifiants comprenant, mais sans s'y limiter, l'en-tête HTTP "X-Playback-Session-ID" qui est un GUID aléatoire qu'Apple Podcasts envoyait pour une "session". Cela rendait possible d'inférer que le même auditeur écoutait même si sa connexion passait d'un réseau à un autre (WiFi à mobile) ou provenait d'un réseau partagé avec d'autres utilisateurs d'Apple Podcasts (par exemple, un lieu de travail partageant une adresse IP publique).
Nous avons exécuté ce système en production avec un ensemble de serveurs mandataires exécutant nginx (configurés avec le drapeau rate_limit sur le ngx_http_core_module) qui faisaient office de mandataire pour nos serveurs de téléchargement et servaient uniquement des fichiers MP3 aux utilisateurs d'Apple Podcasts (par agent utilisateur).
Nous avons analysé périodiquement les journaux de serveur nginx pour reconstruire des événements d'écoute à partir de plages d'octets et avons envoyé des événements de consommation "lecture & pause" à nos serveurs d'analyse principaux pour construire les superbes graphiques et statistiques auxquels nos clients peuvent accéder.
primary analytics servers to build the beautiful graphs and stats our customers can access.
Dans nos tests internes avec la version iOS 10 d'Apple Podcasts (en 2016) et nos serveurs de production sur des connexions WiFi et 3G, nous avons pu atteindre une précision de rapport de consommation à moins de 10 secondes des événements de lecture, de pause et de saut réels.
Bien sûr, ce système n'était pas parfait et présentait plusieurs limitations, certaines auxquelles nous pouvions remédier et d'autres non.
Solutions de contournement et lacunes
En limitant le débit de téléchargement, il y avait un léger impact sur l'expérience d'écoute. Nous avons essayé d'équilibrer et de minimiser cet impact autant que possible tout en maintenant l'intégrité des données analytiques.
Le premier impact était lors du chargement initial. Même sur un réseau de diffusion de contenu rapide, appuyer sur le bouton de démarrage sur un fichier MP3 peut prendre quelques secondes pour être lu. Outre la connexion HTTP au niveau du réseau et les négociations SSL, une partie du retard vient du fait que les fichiers MP3 ont des métadonnées ID3 et XING/INFO au "début" du fichier. Bien que ces métadonnées ne soient pas significativement volumineuses, elles prendraient tout de même plusieurs secondes à télécharger sur une connexion limitée.
Nous avons abordé l'impact du chargement initial en autorisant la connexion à "exploser" initialement (télécharger aussi rapidement que possible) le téléchargement pendant 5 secondes. Cela permettait à l'application de télécharger les métadonnées ainsi que les premières secondes audio aussi rapidement que possible afin qu'il n'y ait aucun impact sur l'utilisateur par rapport à un téléchargement traditionnel.
Lors du traitement des journaux de téléchargement partiels, nos algorithmes tenaient compte du fait que les requêtes initiales avaient une explosion de données audio livrées et attendaient d'autres requêtes de corrélation avant de supposer que la première explosion audio avait été entendue.
Le deuxième impact était pendant la lecture. Parfois, plus souvent sur les connexions mobiles, les téléchargements peuvent être interrompus par des problèmes de connexion (comme le passage en réception et hors réception). Les applications multimédias utilisent un tampon pour permettre au téléchargement de continuer à une vitesse différente de la lecture pour atténuer cela. Mais parce que nous limitons le débit de téléchargement, l'application n'a pas la possibilité de télécharger un long tampon.
Nous avons remédié à cela en veillant à ce que l'application dispose d'un tampon d'environ 10 secondes, de sorte que de courtes interruptions momentanées de connexion puissent encore être tamponnées. Nous avons équilibré ce tampon de manière à ce que les interruptions courtes puissent être atténuées, tout en étant suffisamment courtes pour garantir que l'exactitude de nos événements de consommation puisse toujours être garantie.
Nous avons reconnu que même avec les deux solutions de contournement, l'expérience de lecture n'était pas parfaite et pourrait avoir un impact sur l'expérience d'écoute. Nous avons travaillé en étroite collaboration avec différents clients pour nous assurer qu'ils étaient conscients des limitations avant d'opter pour le système qui échantillonnait aléatoirement seulement une fraction de leurs écoutes en continu de podcasts Apple.
Bien sûr, le plus grand inconvénient de tous est que les lectures téléchargées (soit téléchargées manuellement par l'utilisateur, soit téléchargées automatiquement en arrière-plan par Apple Podcasts) ne pouvaient toujours pas être suivies car elles ne font pas de demande de téléchargement subséquente au serveur.
Et après ?
Dès que nous avons annoncé la fonctionnalité, nous avons eu un flux assez régulier de demandes. Celles-ci allaient de la demande de savoir comment cela fonctionnait, à la question de savoir quand les clients pourraient l'activer, à la question de savoir comment c'était même possible.
Nous avons toujours voulu répondre aux questions que nous ne pouvions pas — divulguer les ingrédients d'une sauce secrète n'est pas toujours une bonne idée. Cependant, Apple s'apprête à fournir les données de consommation de première main et étant donné que nous allons abandonner cette fonctionnalité, nous pensons qu'il est utile de partager notre méthodologie avec l'industrie.
Nous reconnaissons que le système que nous avons développé n'est pas parfait ni assez complet pour remplacer d'autres méthodologies, mais la capacité de jeter un coup d'œil dans la cage de Faraday — ne serait-ce qu'un peu — valait la peine.
Nous attendons avec impatience les informations qu'Apple fournira à l'industrie que nous espérons intégrer afin que nous puissions aider à dresser le tableau le plus complet possible de l'écoute de podcasts pour tous nos clients.
Alors, à tous les créateurs, annonceurs, plateformes et autres acteurs de l'industrie du podcast qui contribuent à faire croître et à mûrir l'écosystème, voici à vous. 2018 devrait être une année intéressante pour nous tous et nous avons hâte.
Retour au blogue